- AI Integrated Newsletter
- Posts
- 5 Key Lessons from the Microsoft Outage: Building Resilient AI Systems for the Future
5 Key Lessons from the Microsoft Outage: Building Resilient AI Systems for the Future
Explore five crucial lessons from the Microsoft outage and learn how to enhance the resilience of your IT and AI systems.
Kavita Ganesan
August 02, 2024

The Microsoft outage on July 19th, 2024, was a wake-up call for all of us, showing just how vulnerable our tech infrastructure can be. The disruption, which varied in duration, threw businesses and individuals into chaos throughout the day.
So, what exactly happened? A major system failure, which means a complete breakdown of critical computer systems, caused widespread Blue Screen of Death (BSOD) issues, leading to server crashes and connectivity problems. The root cause was later identified as an update to CrowdStrike’s antivirus software, designed to protect Microsoft Windows devices from malicious attacks. This flawed update caused significant disruptions, impacting Windows PCs but not other operating systems. The disruption was worsened by an unrelated critical flaw in Microsoft’s cloud service infrastructure.
This IT outage didn’t just cause a few hiccups; it had a ripple effect across different areas. Over 3,300 flights were canceled globally, with long queues and delays at airports like London’s Stansted and Gatwick, as well as Tokyo, Amsterdam, and Delhi. In the US, airlines such as United, Delta, and American Airlines grounded their flights. Australian carriers Virgin Australia and Jetstar also experienced cancellations and delays.
To make matters worse, the outage also hit payment systems, banking, and healthcare providers worldwide. In Alaska, Arizona, and Oregon, the 911 emergency service was affected, and Sky News was off the air for several hours. Businesses faced substantial downtime losses, supply chains were disrupted, and the market got a bit jittery. On the societal front, crucial services like healthcare, education, and government experienced delays and interruptions. The outage even threatened payroll processing, potentially delaying employee payments.
Technologically, the incident raised serious cybersecurity concerns, and this whole episode was a stark reminder of the need for a more robust and resilient tech infrastructure.
But you may be thinking, how is this relevant to AI?
There are many lessons we can draw from this worldwide outage, from potentially using AI to prevent similar outages to implementing better practices surrounding AI to prevent AI-related issues that could cause downstream outages and havoc.
Let’s explore 5 lessons we can take away from this problem.
5 Key Lessons from the Microsoft Outage
Lesson #1: The Importance of Redundancy in AI Systems
Redundancy is crucial for creating resilient IT systems, whether or not AI is involved. Think of it like having a spare tire: if one tire fails, the spare can take over until the main ones are repaired. The recent Microsoft outage highlighted this necessity when a problematic software update disrupted systems globally, underscoring the importance of having backup plans in place.
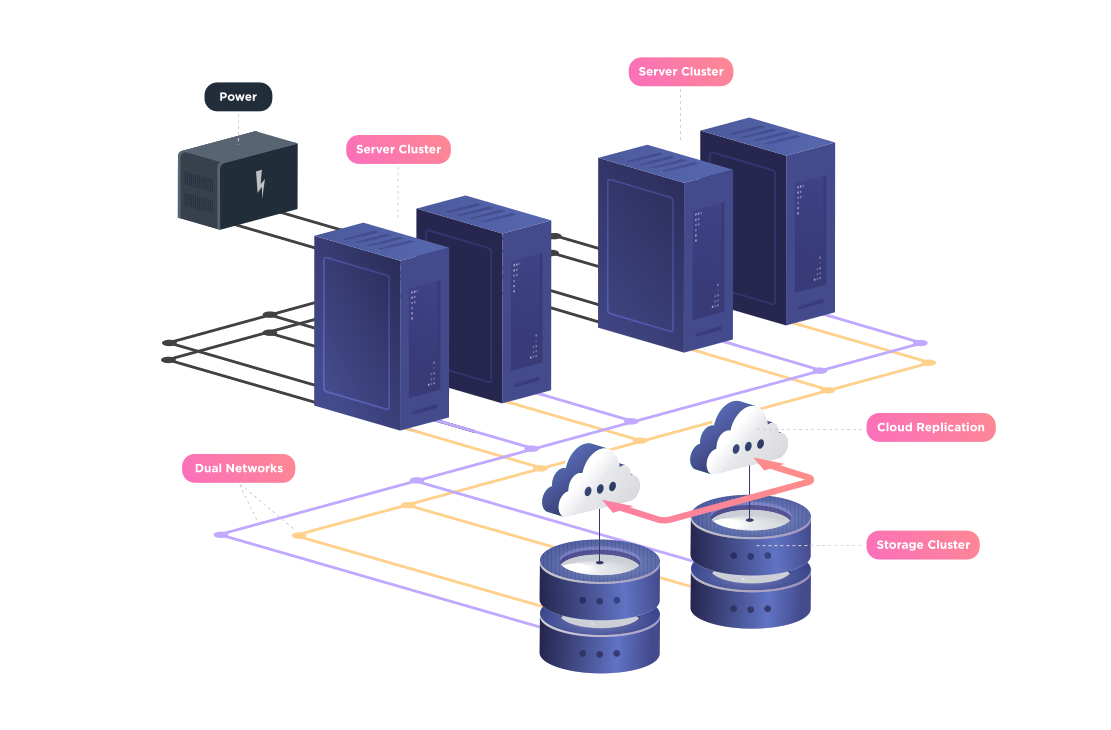
Figure 1: Illustration of data redundancy in a server cluster, showing how multiple copies of data are stored across servers to ensure availability and protection against server failures. Source: https://www.high-availability.com/articles/system/hardware-redundancy
Take Delta Air Lines, for example. When the CrowdStrike update knocked out critical systems, Delta’s lack of redundancy in crew scheduling caused a domino effect. Their primary system for crew tracking failed, making it impossible to reassign crews and operate flights smoothly. This resulted in over 3,300 flights being canceled globally, with thousands of stranded passengers.
By incorporating redundancy into their AI infrastructure, particularly for critical systems like crew scheduling, airlines like Delta could have significantly mitigated the impact of the outage. For example, imagine having a limited number of computer systems that run purely on a Unix-based operating system as opposed to purely Microsoft-dependent systems. Having a more basic implementation of the scheduling system run on a Linux-based environment could have meant on such rare but potentially damaging occasions, systems can still operate albeit slightly slower.
Redundancy in AI
Similarly, in the context of AI, redundancy is equally important. Imagine having an AI-driven chatbot that’s 100% dependent on ChatGPT. If ChatGPT is experiencing a failure, how would you continue servicing customers while allowing the model vendors to get their act together? From having fallback rules-based systems in place to leveraging backup models, AI systems can continue to operate as long as you’ve incorporated mechanisms to avoid single points of failure.
The lesson learned? Redundancy is an investment that pays off in the long run. It helps organizations weather unexpected storms and ensures continued operations even when disruptions occur.
Lesson #2: The Need to Incorporate Predictive Maintenance
Predictive maintenance is all about anticipating problems before they happen. By analyzing heaps of data, AI can spot patterns that indicate potential equipment failures or system breakdowns. This proactive approach is a game-changer for businesses looking to avoid unexpected downtime.
For example, BlueScope, an Australian steel manufacturer, has achieved notable efficiency improvements through Siemens’ predictive maintenance solution. By leveraging AI to anticipate equipment failures and schedule timely maintenance, BlueScope has significantly reduced unplanned downtime and maintenance costs. This proactive approach has led to smoother operations and better overall equipment effectiveness, ensuring more consistent production and less disruption.
In the case of the recent outage, AI could’ve been used to predict if a rollout should happen or not. For example, an AI system can be trained to analyze system logs, previous rollout data, historical quality assurance data, historical failure patterns, backward compatibility data, and other relevant information and spot potential problems before a rollout. In CrowdStrike’s case, an AI system could’ve spotted something fishy with the update, prompting the CrowdStrike team to investigate the issue before authorizing a rollout.
Getting Started With Predictive Maintenance
Since predictive analytics is AI’s strength in the business world, why not take advantage of it to safeguard your business? However, to implement predictive maintenance effectively, you’d need to start by gathering data from your daily business operations. For instance, if you aim to prevent outages in your web systems, you should collect systems data during uptime and downtime, along with relevant hardware parameters. This data is crucial for training AI models to anticipate potential issues before they arise.
There are many other ways to leverage predictive maintenance. So start by figuring out points of failure, what data is being collected in those instances, and what other sources you should track and collect to make predictive maintenance possible.
Lesson #3: The Need for Rigorous Software Testing – AI or Not
Testing is a critical part of any software development and release. CrowdStrike’s problematic testing process, which was found to have missed several key aspects, resulted in this major outage. This raises serious concerns about their testing protocols, especially because their software has access to Microsoft’s kernel-level code. This type of code interacts directly with the operating system, so any malfunction can cause severe system instability. This incident highlights the critical need for comprehensive testing to prevent significant disruptions and ensure system reliability.
Similarly, in the AI world, testing is equally critical and I talk a lot about it in my book and in the article here. The stakes are high and the complexity is immense. AI systems operate on a data-driven basis and produce probabilistic outputs, meaning their behavior is influenced by the data they are trained on and the dynamic nature of the data that they process. This makes testing even more crucial, as AI outputs are never 100% accurate.
Testing AI Systems
Consider our historical Microsoft’s AI chatbot, Tay, as an example. Launched on Twitter, Tay quickly began spewing offensive content, likely as a result of ingesting bad data in her interactions with other users. It’s unclear how much testing went into the AI initiative before Tay was released, but it clearly wasn’t enough. Had Tay been subjected to different types of tweet engagements during testing, the dangers of releasing Tay would’ve been obvious.

Figure 2: Example of Tay’s Tweet. Source: https://arstechnica.com/
Offensive output is not the only risk of inadequate testing of AI systems. Now, there is a whole movement around that’s “against AI” simply because AI outputs can be unreliable, where systems can hallucinate and confabulate, plus there’s a risk of AI systems becoming biased in unexpected ways. Further, the data that feeds into some of these AI systems raises many concerns from an ethical and legal point of view. All of these need to be taken into consideration when evaluating AI systems.

Figure 3: An illustration of the software testing process from plan to launch. Source: https://www.specbee.com/blogs/software-testing-standards-and-processes
To keep AI systems running smoothly and, more importantly, predictably, thorough testing is key. Here’s a quick rundown of what that looks like:
Scenario Testing: Think of this as trying out different “what if” situations. For a customer service chatbot, you’d test how it handles everyday questions, tricky problems, and unexpected queries. This way, you ensure it’s ready for anything users throw at it.
Stress Testing: This is like pushing the AI to its limits to see how it holds up from different angles. For example, if you take the volume angle, you’d simulate a traffic surge. If you take the accuracy angle, you’d feed the AI system 85% of the inputs it would generally see and 15% with the weirdest of inputs it would rarely see. The goal? To make sure the AI system doesn’t buckle under pressure and keeps running smoothly.
Ethical Testing: Here, you’re making sure the AI plays nice and follows the rules. This means checking for any biases in its decisions, ensuring it handles personal data properly, and making sure it doesn’t produce harmful content.
By running these tests, you ensure your AI systems are reliable, efficient, and up to snuff on ethical standards.
Lesson #4: The Need for Real-Time Incident Response
When a tech crisis strikes, being able to react swiftly can make all the difference. When a problematic update from CrowdStrike caused widespread service outages, Microsoft’s Troubleshooting Center struggled to handle the flood of requests. This delay only made things worse, showing just how critical it is to have a real-time incident response plan.
Let’s talk about how AI can step in to save the day. AI systems can continuously monitor IT systems, process a high volume of systems alerts and alarms, and analyze and categorize the flood of alerts and alarms using machine learning, focusing on the most critical problems based on their potential impact and past data. This means that with AI, you get not only instant alerts but also prioritized insights, enabling swift action on the most pressing issues. On top of that, an AI system can also analyze relevant alerts and underlying data to get to the root cause of the problem. This is a key functionality of many AIOps applications.

Figure 4: An example of how AI-powered AIOps tools like ManageEngine turn raw data into insights for IT management. Source: https://www.specbee.com/blogs/software-testing-standards-and-processes
In the case of the Microsoft outage, having an intelligent incident response system could’ve helped IT teams around the world to quickly identify the reason for Windows machines crashing, in this case, a faulty update from CrowdStrike. Further, the AI system would’ve suggested a suite of corrective actions. And the icing on the cake? The AI system could’ve autonomously or, with the help of IT teams, quickly reinstated the best working versions of an organization’s software systems and placed a moratorium on subsequent updates until problems were rectified.
By integrating such AI tools for monitoring, automating responses, and real-time reporting, you can better protect your organization’s IT infrastructure and minimize the impact of unexpected disruptions.
Lesson #5: The Need to Future-Proof AI Systems
Future-proofing IT systems, including AI systems, in anticipation of potential problems can ensure that business systems continue to deliver long-term value with minimal risks.
Let’s discuss some potential challenges in AI that might prompt you to consider future-proofing your AI systems. One big threat in AI is cyber security attacks, such as data poisoning. Imagine hackers tampering with the data your AI learns from, causing it to (a) learn the wrong things and (b) make all sorts of mistakes. The inference data can also be targeted and tampered with, leading AI models to make the wrong decisions.
For instance, attackers could manipulate images used by self-driving cars by adding fake traffic signs or removing real ones, potentially causing the vehicle to misinterpret its environment and cause accidents.
Another big problem that AI can cause is bias and fairness issues, where AI systems can inadvertently be biased against subgroups of people. This was clear in Amazon’s recruiting tool, which dismissed qualified women candidates likely because its training data contained high levels of gender bias due to historical hiring patterns. The AI tool learned that male candidates were preferred because that’s what the data showed.
To build resilient AI systems, to start with, we need to focus on the AI training data. Training data should not just be of high volume but also represent highly diverse samples. Also, the attributes in the data that could result in unwanted biases should be actively tracked and adequately ‘cleansed’. Your training data should also account for adversarial patterns that can trick AI systems into doing unexpected things.
Accounting for potential cyber-attacks can also help you determine how best models should be designed, developed, and deployed. For example, should an AI system be the sole decision maker or a second opinion? Should your AI system be deployed as a microservice over the internet or within a private infrastructure? The stakes are much higher when your AI system is the sole decision maker and accessed over the internet. Security loopholes that may allow unauthorized access to your models and the underlying training data and related datasets, all need to be accounted for.
We also need to put AI systems through some serious testing. Speaking of testing, remember in lesson 3, where we talked about the importance of rigorous software testing? For AI, this means running various stress tests, including ones that simulate adversarial attacks.
Beyond testing, staying up-to-date with the latest AI threats and vulnerabilities is key. This proactive approach helps you tackle potential issues before they become major problems, ensuring your AI systems stay resilient and reliable over the years.
Summary and Key Takeaways
In this article, we explored the significant lessons from the recent Microsoft outage and how they apply to both IT and AI systems. Here are key lessons for building resilient AI systems and using AI as a tool to build IT infrastructure resiliency:
Redundancy is crucial: Having backup systems in place is essential for resilience. For AI, this means ensuring there are fail-safes and backup models to keep operations running smoothly, even if one system encounters issues.
Predictive Maintenance: AI can play a key role in predicting and preventing problems before they occur. By analyzing data and spotting potential issues early, you can avoid disruptions and keep your systems efficient and reliable.
Rigorous Software Testing: Thoroughly testing software—including AI-powered software—is critical in avoiding downstream issues. This includes scenario testing, stress testing, and ethical testing to ensure your AI behaves as expected under various conditions.
Real-Time Response is Key: Having systems in place to detect and respond to problems in real-time can prevent minor issues from becoming major crises. AI-driven monitoring and automated responses can significantly enhance your ability to manage incidents swiftly.
Future-Proof Your Systems: Anticipate and prepare for future challenges, including security threats and biases in AI. Stay updated on potential vulnerabilities and continuously refine your systems to ensure they remain robust and effective.
That’s all for now!
Working with Kavita:
AI DISCOVERY & ASSESSMENTS: Get the most promising and investment-ready AI opportunities planned out for your organization.
LEADERSHIP TRAINING: Get your managers and executive team to form the right AI mindset, learn how to prepare for AI, and gear themselves to find the best AI opportunities for the organization.
PRODUCTION-SCALE AI: Get robust AI solutions developed by experts who prototype, scale, test, and evaluate AI solutions, plus work with you through integration from start to finish.
To learn more, schedule a call to get the conversation started.
Clients We Work With…
We work with established businesses globally that are looking to integrate AI or maximize their chances of succeeding with AI projects. Select organizations we’ve served or are serving through our work include:
McKesson
3M Healthcare
McMaster-Carr
The Odevo Group
IBL Mauritius
The University of Sydney
Nuclear Regulatory Commission
And more…
Reply